

The Opus 4.7 vs gpt-6 question is not really about which model scores higher on a leaderboard. It’s about which one you can actually use today, and whether waiting for the other one makes any practical sense. As of April 2026, Anthropic’s Opus 4.7 is generally available and shipping real results. GPT-6, codenamed “Spud” internally at OpenAI, is still in limited beta with a rumored full rollout sometime in late April or May.
That gap matters more than most comparisons acknowledge. One model is in your hands right now. The other is still a set of benchmarks, roadmap slides, and early access reports. We’ll cover both honestly — what each model does well, where each one stumbles, and who should be using which.
What Anthropic Opus 4.7 Actually Does
Opus 4.7 launched on April 16, 2026, as Anthropic’s most capable publicly available model. Its design philosophy is narrow but sharp: long-horizon tasks, agentic coding, and rigorous document understanding. Think of it less as a chatbot and more as a technical collaborator that can hold a large codebase in mind, plan multiple steps, and check its own work before responding.
The self-verification feature is the biggest practical upgrade from Opus 4.6. The model now audits its own outputs internally before surfacing an answer, which cuts hallucinations meaningfully in complex coding tasks. For developers running multi-file refactors or debugging sprawling APIs, that internal cross-check is the difference between a useful output and a plausible-sounding wrong one.
The Benchmarks That Matter
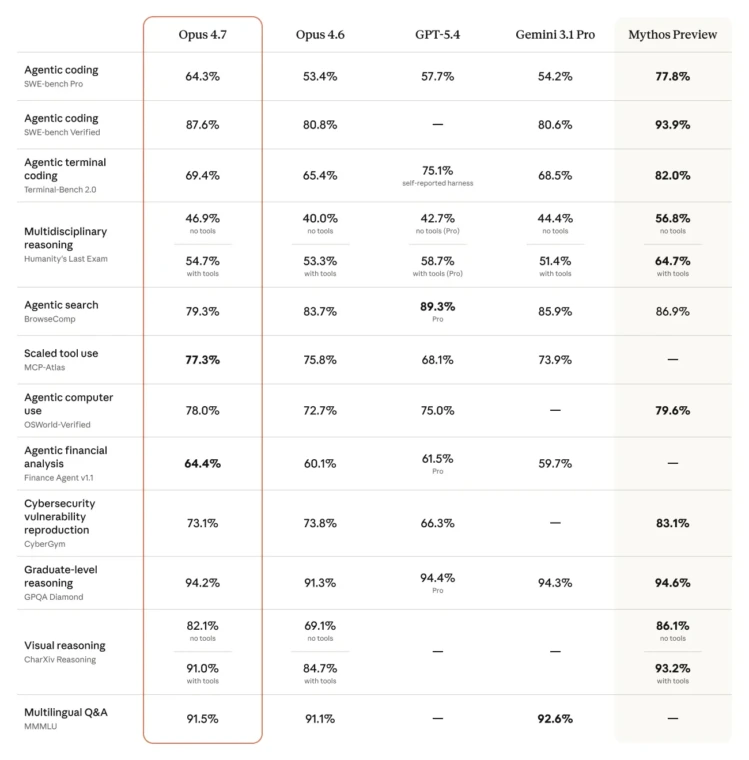
Anthropic opus 4.7 scores 87.6% on SWE-bench Verified and 70% on CursorBench.
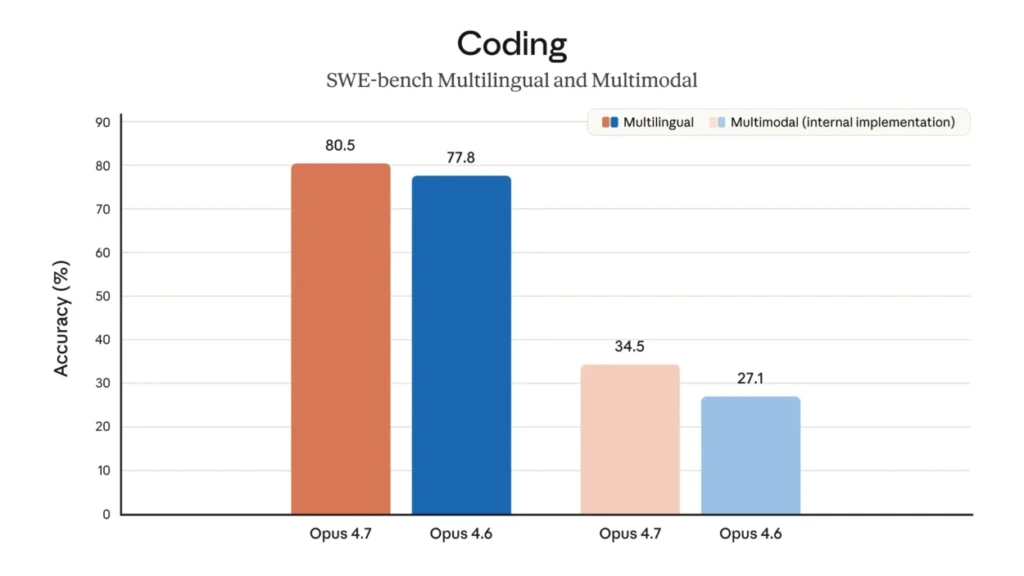
Those numbers are 12 to 13 percentage points above Opus 4.6, and they hold up across real-world coding tasks, not just controlled lab conditions. The vision upgrade is equally significant: image resolution support now reaches approximately 3.75 megapixels, with 1:1 pixel mapping on the long edge. For anyone parsing dense UI screenshots, architectural diagrams, or scanned documents, that is a substantial jump in accuracy.
The context window sits at 200K tokens in standard access and scales to 1M tokens for enterprise accounts. Pricing is $5.00 per million input tokens and $25.00 per million output tokens.
What Breaks With Opus 4.7 (And How to Fix It)
Opus 4.7 is production-ready, but it ships with two architectural changes that catch beginners mid-workflow. Both are fixable in under five minutes once you know what triggered them.
Issue 1: API 400 Errors on Existing Calls
Anthropic removed temperature, top_p, and top_k from Opus 4.7 entirely. If your current API integration passes any of those parameters, some providers will throw a 400 Bad Request error on strict validation.
- Open your API call configuration
- Remove
temperature,top_p, andtop_kwherever they appear - Opus 4.7 manages output quality through its own adaptive reasoning; those controls no longer apply
Issue 2: Responses That Run Too Long
The model’s internal self-verification loop is thorough by design. On simple prompts, that thoroughness produces more explanation than you need.
- Set the
verbosityparameter tolowormediumfor everyday tasks - Reserve higher effort levels for complex coding or research queries
Issue 3: Token Usage Spikes
Adaptive thinking draws more tokens than a standard response on hard queries. Left unchecked, this hits usage budgets faster than expected.
- Adjust ceiling values based on actual task complexity in your specific workflow
- Set a hard ceiling using
max_tokensfrom the start - Monitor token consumption per query during the first week of integration
What We Actually Know About OpenAI’s GPT-6
PT-6 is designed around three capabilities that distinguish it from everything OpenAI has shipped before.
First, persistent long-term memory across sessions, meaning the model can carry context, preferences, and prior decisions forward across days or weeks of work.
Second, true agentic autonomy, where GPT-6 proactively selects tools, browses the web, and executes multi-step workflows without waiting for instruction at each step.
Third, it runs on OpenAI’s Stargate supercomputing infrastructure, which gives it a hardware foundation built specifically for advanced reasoning and mathematical tasks.
The multimodal scope is also broader than Opus 4.7. GPT-6 is being designed to handle text, images, video, and audio within the same workflow. The context window is rumored to be 1M tokens or above, and pricing benchmarks against GPT-5.4’s current rate of $2.50 per million input tokens and $15.00 per million output tokens, though GPT-6 pricing has not been confirmed publicly.
What makes GPT-6 a harder recommendation right now is not capability. It’s access. Limited beta means most developers and builders are looking at a waitlist, uncertain timelines, and early-access behavior that tends to be less predictable than a stable general availability release.
Opus 4.7 vs GPT-6: Let’s Compare Them
| Feature | Claude Opus 4.7 | GPT-6 |
|---|---|---|
| Availability | Generally Available (April 16, 2026) | Limited Beta (Late April/May 2026) |
| Context Window | 200K / 1M (Enterprise) | 1M+ (Rumored) |
| Coding Benchmark | 87.6% SWE-bench, 70% CursorBench | Not publicly verified |
| Vision | 3.75MP, 1:1 pixel mapping | Text, Image, Video, Audio |
| Memory | Session-based | Persistent across sessions (rumored) |
| Thinking Mode | Adaptive (model-controlled) | Agentic autonomy |
| Pricing (Input/Output) | $5.00 / $25.00 per MTok | Unconfirmed (GPT-5.4: $2.50/$15.00) |
| API Stability | Stable, production-ready | Early access, variable behavior |
| Self-Verification | Yes | Not confirmed |
| Parameter Control | No temp/top_p/top_k | Standard controls available |
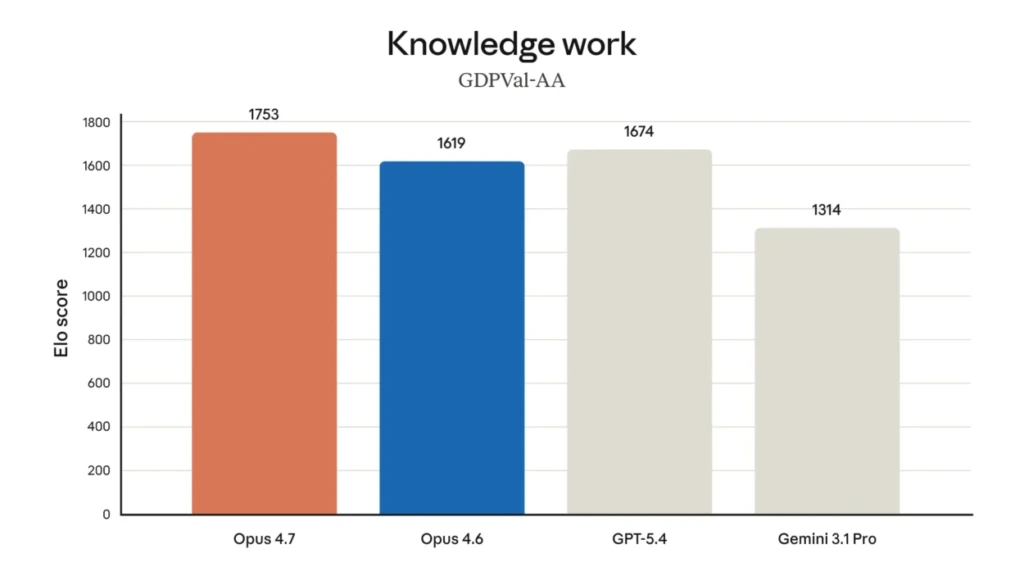
That shows Opus 4.7 (1753 Elo) directly against GPT-5.4 (1674 Elo) and Gemini 3.1 Pro (1314 Elo)
Who Should Use Opus 4.7 Right Now
Opus 4.7 is the right starting point for the majority of developers, researchers, and AI beginners working on real projects in 2026. The 87.6% SWE-bench Verified score reflects performance on actual GitHub repositories pulled from production codebases and not synthetic test conditions.
For anyone running multi-file refactors, debugging complex APIs, or reviewing long technical documents, that benchmark translates directly into fewer wrong answers reaching your screen.
The self-verification feature is what makes it particularly well-suited for beginners. Because the model audits its own outputs before responding, you spend less time fact-checking and re-prompting. That internal correction loop is especially valuable when you are still building your instinct for spotting AI errors.
Here is who gets the most out of Opus 4.7 right now:
- Freelance developers and indie builders running coding or research workflows
- Small product teams that need a stable, documented model with predictable API behavior
- Beginners using AI tools for the first time who need reliable outputs without beta-stage surprises
- Anyone processing dense visual content like UI screenshots, scanned documents, or architectural diagrams, where the 3.75MP vision upgrade makes a direct difference
There is no waitlist, no uncertain pricing, and no shifting behavior between early-access updates. For most people reading this in April 2026, that stability alone is worth more than a rumored benchmark.
Who Should Wait for GPT-6
GPT-6 is worth planning for, but not worth building on yet. The features that distinguish it, persistent long-term memory, true agentic autonomy, and Stargate-backed reasoning depth, are genuinely compelling for a specific class of product. The honest constraint is that none of those features are in stable general availability today.
The teams that have a legitimate reason to prioritize GPT-6 access fall into a narrow category:
- Long-term product builders developing AI-native SaaS tools where persistent memory across sessions changes what the product can actually deliver — a support tool that remembers every prior interaction, or a research assistant that carries methodology decisions forward across weeks.
- Enterprise research teams working on advanced math, scientific reasoning, or high-volume agentic workflows where the Stargate infrastructure advantage may translate into meaningful reasoning gains over anything currently available.
- Large engineering teams with the capacity to absorb beta-stage unpredictability — variable behavior between updates, unconfirmed pricing, and access timelines that may shift.
For everyone outside that group, building a production workflow on a limited beta in April 2026 introduces risk that outweighs the upside, but if you are a developer, then maybe OpenAI’s Codex will help you Check Out
The practical move is to start with Opus 4.7 now and layer GPT-6 into specific workflows once it reaches full general availability and its memory features clear the beta stage.
So what you should do
Start with Opus 4.7. It is available, benchmarked, and production-stable. For coding, document analysis, vision tasks, and agentic research workflows, it outperforms every previous Anthropic model by a meaningful margin and holds its own against the best alternatives shipping today.
When GPT-6 reaches full general availability and its memory and agentic features move out of beta, the calculus will shift for specific use cases.
At that point, the right move for most teams will be running both Opus 4.7 for coding and document-heavy tasks and GPT-6 for long-horizon personalized workflows where session memory changes outcomes.
The opus 4.7 vs. GPT -6 comparison will look very different in six months. For now, one model ship works, and one ship’s promises. Anthropic opus 4.7 is the one shipping work.
Conclusion
Anthropic Opus 4.7 is the most capable, stable, and accessible model available in April 2026 for developers, researchers, and AI beginners building real things. GPT-6 is a compelling roadmap — and likely a serious competitor once it fully ships — but roadmaps do not finish your pull requests.
If you are evaluating Opus 4.7 vs gpt-6 for an active project or learning path, start with what you can actually run today. Check Anthropic’s official release notes at platform.claude.com for API specifics, and monitor OpenAI’s model index page for GPT-6 access updates as they roll out.


